シミュの中で完璧なロボットは、なぜ現実で転ぶのか——sim2realギャップを実際に測る
前回、倒立振子で見たのはこうでした——きれいなモデルが書ける問題では、モデルを渡された古典制御(LQR)が、データ0で強化学習に完勝する。では、モデルが書けない問題ではどうなるか。そして、そこで学んだ方策は現実でも動くのか。今日は、歩くロボットを実際に学習させ、最後の問いを実測します。全部、手元のGPUでオフラインに走らせた本物の数字です。
第一幕:チーターに、走り方を教える
題材は MuJoCo の HalfCheetah——二次元の「チーター」が、関節にトルクをかけて前へ走る課題です。倒立振子と違い、地面との接触が複雑で、きれいな運動方程式を書いて制御器に渡す、という手が使えません。モデルが無い。ここが強化学習(RL)の出番です。
RLには物理を教えません。最初はデタラメに関節を動かし(ランダム方策の報酬は −263=その場でもがくだけ)、たまたま前に進めた動きを少しずつ強化していく。標準的な実装(PPO, stable-baselines3)で30万ステップ学習させると——
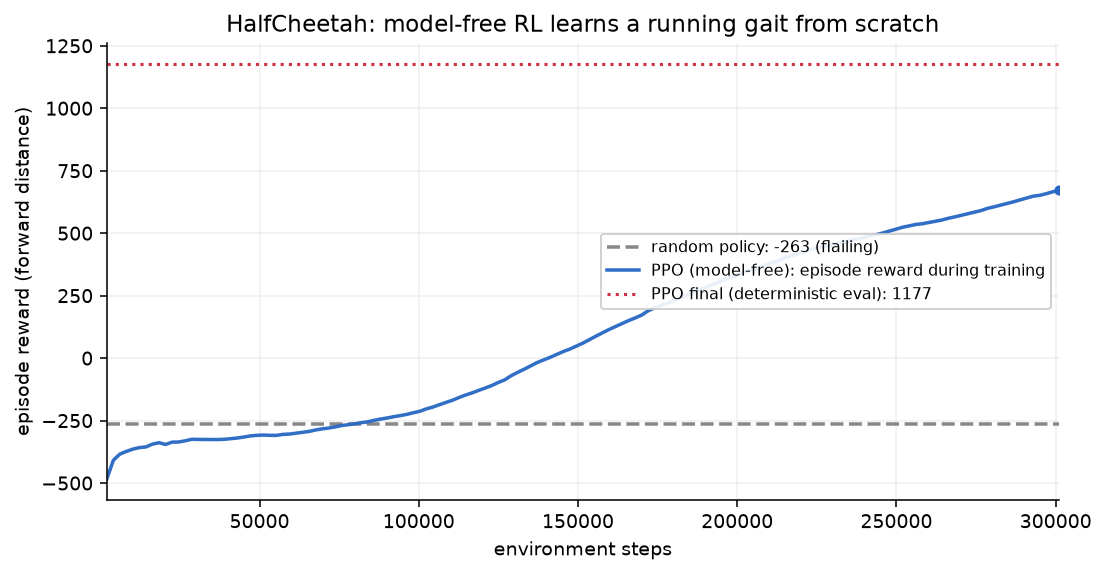
ランダムの −263 から、決定論評価(ばらつきを止めた「本番モード」での評価)で +1177 へ。モデルを一切渡さずに、0から走る歩容を獲得しました。前回のLQRが「モデルで払う」なら、こちらは「サンプルで払う」。約30万ステップの経験が授業料です。(公平のため:PPOは中庸な手法で、SAC等ならもっと上がります。論点は上限でなく「モデル無しで0から学べる」ことです。)
これだけ見れば、めでたしです。RLは歩行を解いた。ただし、ひとつ但し書きがつきます——「シミュレータの中では」。
第二幕:完璧なのは「シミュの中で」だけ
学習した方策は、学習に使ったシミュレータの物理に対して最適化されています。けれど現実のロボットは、シミュとぴったり同じではない。実機の関節は少し重いかもしれない、床は少し滑るかもしれない、モーターの指令には必ずわずかな遅延がある。
そこで、学習済みの方策をそのまま(再学習なしで)、訓練時と少し違う物理に置いて評価しました。質量・摩擦・作動遅延を、それぞれ振ってみます。
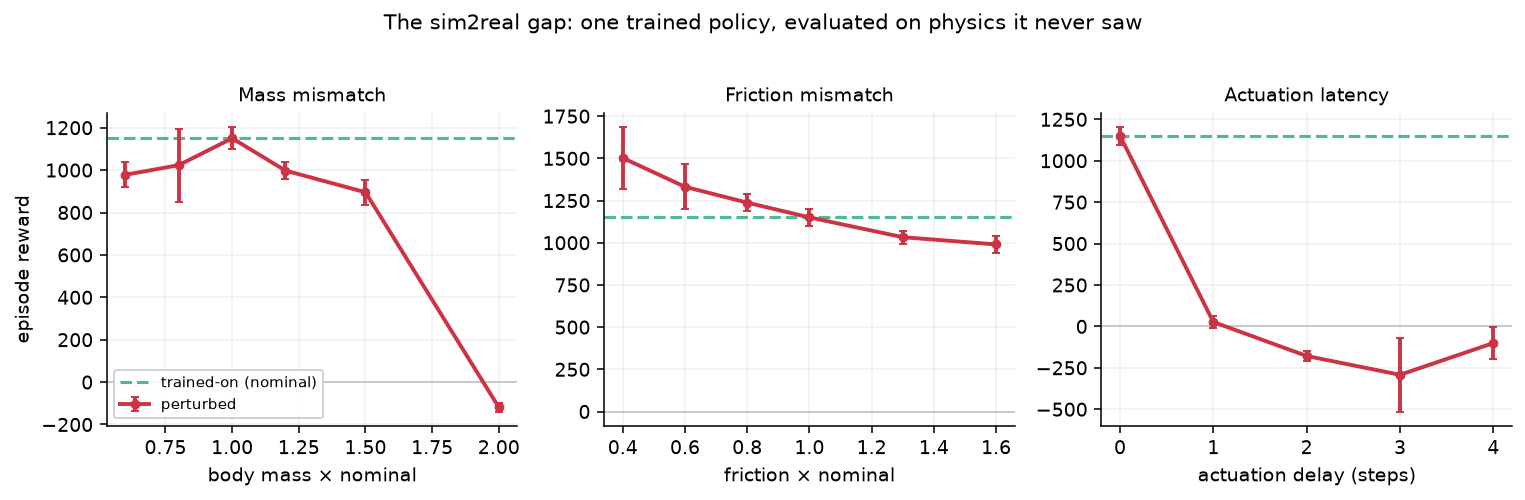
結果は鮮烈でした。
- 質量:1.5倍までは8割前後を保つ(緩やかに劣化)。だが2倍で崩壊(報酬がマイナスに=重すぎて走れない)。
- 作動遅延:これが効いた。たった1ステップの遅れで、報酬は1150から26へ——ほぼ完全な崩壊。2ステップ以上で転倒します。実機の作動には必ず遅延があり、訓練シミュには無かった。シミュ内で完璧な方策が、1ステップの遅れで壊れる。
これが sim2realギャップです。本シリーズ「凸包」で繰り返してきた 「凸包より下 ≠ 現実」——計算上の最適は、現実の最適ではない——の、ロボット版そのもの。比喩ではなく、実測された谷です。
ひとつ、正直な但し書きを。ズレは必ずしも「悪化」ではありません。摩擦を下げると、報酬はむしろ上がりました(0.4倍で131%)。滑りやすい床を、方策が「速く滑る」ことに利用したからです。「違う」と「悪い」は別物。ここを混同しないのも、世界トップレベルの読み方です。
第三幕:「直す」側にも、ちゃんと値札がある
では、どう直すか。最も標準的な手がドメインrandomization (DR)——訓練のあいだ、わざと物理をランダムに揺らす。質量も遅延も毎エピソード変えて学習させれば、方策は「ひとつの物理」に過適合できず、幅のある物理に耐えることを強いられます。
実際にDR版の方策を学習し、同じ条件で比べました。
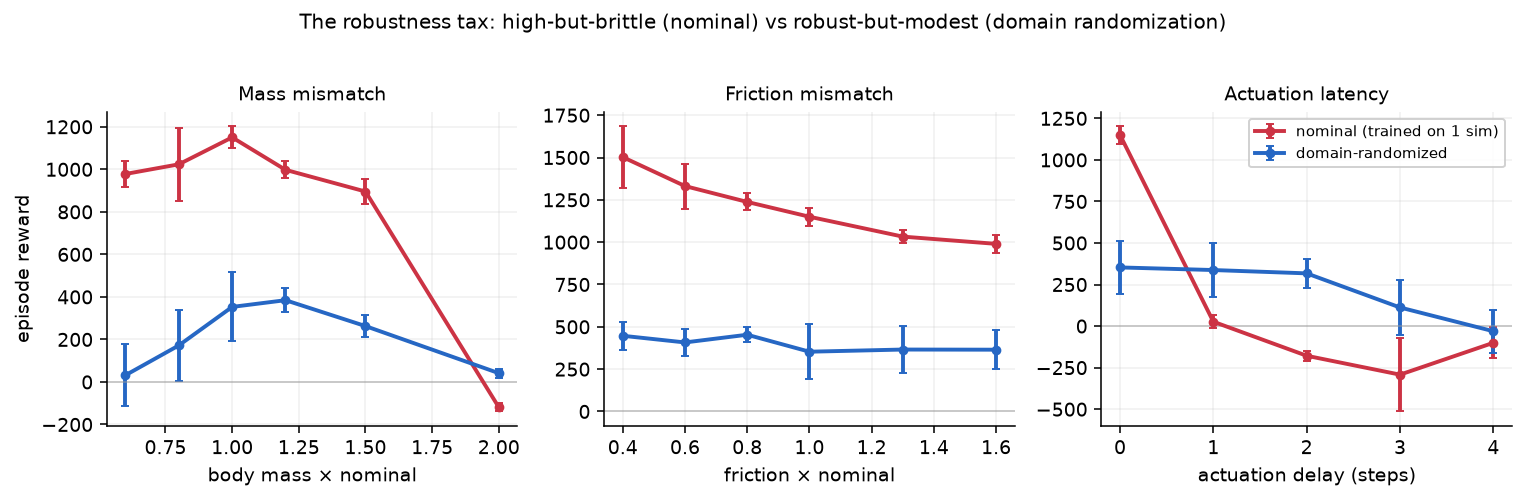
予想どおり、そして正直に——トレードオフが出ました。
- 頑健さは買えた:遅延1ステップで、nominalは26まで落ちたのに、DRは337を保つ。質量2倍でもDRは生き残る。nominalを殺した摂動を、DRは耐える。
- だが、値札がある:DRの無摂動時のピークは 353——nominalの 1150 から大きく下がりました。あらゆる物理に備えるぶん、どの物理でも器用貧乏になる。これが **robustness税(頑健性の税)**です。
どちらが「良い」かは、現実に遅延があるかどうかで完全に決まります。遅延ゼロの理想世界ならnominalが圧勝、現実に1〜2ステップの遅延があるならDRが圧勝。タダで頑健にはなれない。
これは玩具の話ではありません。OpenAIが片手でルービックキューブを解いたロボット(2019)は、まさにこのDRの極致でした。彼らは「普通のDRでは足りない」ことに突き当たり、難易度を自動で上げ続ける Automatic Domain Randomization を発明した。その方策は頑健で、学習中に一度も見ていない状況——ぬいぐるみのキリンで小突かれても——キューブを落とさなかった。DRという考え自体も、2017年(Tobinら)の sim2real 研究から来ています。私たちがチーターで見た谷とトレードオフは、最前線が格闘しているものと同じ構造です。
さらに一歩:「揺らす」のか「測って直す」のか
DRは「現実がどこにあるか分からないから、広く備える」戦略です。けれどもし、現実の遅延や質量を実際に測れたら——その値に合わせて訓練・適応すればいい。これが system identification(同定) の発想で、原理上、闇雲なDRより上に行けます。ただし「測れるなら」が条件。測れない量(複雑な接触や摩擦)に対しては、OpenAIがそうしたように、結局DRで広く張るしかない。測れるものは測って直す、測れないものは広く備える——この線引きこそ、エンジニアリングの判断です。
(方法の注:本記事の各数値は、単一の学習済み方策・1シードでの評価結果です(各条件12エピソード)。傾向ははっきり出ていますが、定量値そのものはシード差を含みます。再現コードは公開しています。)
まとめ:A→B→C、そして「タダの手はない」
3つの実験が、ひとつの線で繋がりました。
- A(倒立振子):モデルがある → 古典制御が、データ0で勝つ。
- B(歩行):モデルが無い → 強化学習が、サンプルを払って勝つ。
- C(sim2real):だがRLが学んだのはシミュのモデルで、世界はシミュではない。谷は実在し、測れて、最も油断するところ(遅延)で最も深い。DRで頑健さは買えるが、ピークで支払う。
通底するのは——タダの手はない。モデルか、サンプルか、頑健性か、どこかで必ず払う。そして本当の腕とは、「どこで払っているか」を測ることだ。 これがこのサイトの背骨(価値は派手な表面でなく、その下の測定にある)の、ロボットの足元での姿です。
ここまでが「フィジカルAI」——身体を持つAIが、まさにこの谷と日々格闘しています。次回はその全体像を、もう少し俯瞰してみます。
なお、ここで実演した谷を文献と議論の側から掘り下げた姉妹編が2本あります——sim2realは、学習問題に見せかけた計測問題だとドメインランダム化は技術ではなく、告白だ。今日の数字は、その主張を手元で測り直したものです。
この記事はAIが下書きし、人間が編集・公開しています。