倒立振子を、制御とRLの両方で立たせてみた——賢い方が、無料で勝つわけではない
棒を一本、台車の上にヒンジで立てる。台車を左右に押して、棒を倒さないように保つ——これが倒立振子です。言葉にすれば一行。けれどこの問題は、40年にわたって制御とAIの最小の実験場であり続けてきました。小さくて全部見通せるのに、本質的な難しさ——不安定な釣り合いを、能動的に保ち続ける——を、歩くロボットとそっくり同じ形で持っているからです。
今日はこれを、二つの流派で実際に解かせて、同じ物差しで測りました。シミュレータは MuJoCo(Multi-Joint dynamics with Contact)の InvertedPendulum。物差しは「1000ステップ中、倒さずに何ステップ立っていられたか」。流派は、古典制御の LQR と、強化学習の REINFORCE。全部、手元のGPUでオフラインに走らせた、本物の数字です。
流派A:「モデルを渡す」——LQR
LQRには、世界の物理を教えます。倒立点のまわりで運動方程式を線形化し(=倒立点の近くだけ、複雑な物理を直線で近似する)、「いまどれだけ傾いているか」から「どれだけ押し返すか」を、数学的に最適な形で計算させる。乱暴に一行で言えば——
押す力 = −(傾きや速度のズレ)×(モデルから決まる重み)
「ズレに比例して押し返す」だけ。ただしその重みは、物理を知っているからこそ決まります。世界のルールブックを手渡された者が、完璧にプレイする。
結果:1000ステップ中1000ステップ、成功率100%。使った学習データはゼロ。
流派B:「サンプルを渡す」——強化学習
REINFORCEには、物理を一切教えません。最初はデタラメに押し、たまたま棒が少し長く立つと、その方向へ自分を少しだけ寄せていく。試行錯誤だけ。マニュアルなしで、転びながら自転車を覚えるのに近い。
結果が下の図です。600エピソード・約43,000ステップ練習しても、最終評価は1000中535ステップ。しかも不安定で、学習曲線はエピソード350あたりで一度ピーク(平均207ステップ)に届いた後、崩れ、また少し戻る——高分散な方策勾配の、教科書どおりの振る舞いです。学習を通して、一度も1000ステップを立ち切れませんでした。
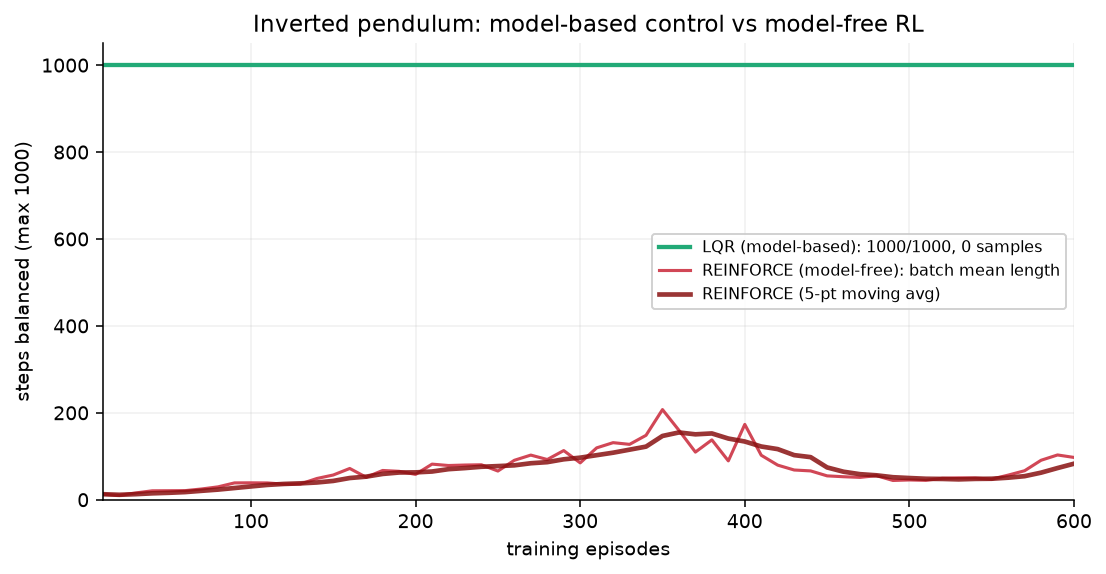
緑の直線がLQR(データ0で天井に張り付く)、赤がREINFORCEの学習曲線です。同じ問題、同じ物差しで、これだけ違う。
同じ問題、違う「通貨」
ここが今日の核心です。どちらも棒は立てられる。けれど、支払う通貨が違う。
- LQR は「モデル」で払う。物理を知っている(測れている)必要がある。その代わり、データ0で完璧。
- 強化学習 は「サンプルと不安定さ」で払う。モデルは要らない。その代わり、何万回も転び、今回は半分しか立てなかった。
(公平のための補足:今回のREINFORCEは最も素朴なRLです。PPOやSACといった現代的な手法なら、もっと安定して立てます。ここで見たいのは「RLの上限」ではなく、支払う通貨が違うという構造のほうです。)
「AIが棒を立てられるようになった!」という派手な見出しは、難所でも価値の中心でもありません。本当の問いは——それは何を、どこで支払ったのか。賢く見える方法は、無料ではない。必ずどこかで払っている。その「どこ」を測るのが、エンジニアリングの本体です。これはバンディットの記事で見た「漸近的な賢さは有限の予算を支配しない」と、舞台を変えた同じ教訓です。
では、強化学習は要らないのか?——歴史がそれに答える
いいえ。RLが存在する理由は、まさにモデルが書けない場合にあります。きれいな振子の運動方程式は書けても、デコボコの地面を接触しながら歩くロボットの方程式は、同じようには書けない。モデルが尽きるところから、RLの出番が始まります。
面白いのは、この分野の二本の柱が、どちらも**「運動」と「脳」を理解しようとした人たち**から生まれていることです。
- 倒立振子が学習制御のベンチマークになったのは 1983年、Barto・Sutton・Anderson の論文 “Neuronlike adaptive elements that can solve difficult learning control problems”(IEEE Trans. SMC-13: 834–846)から。後の actor-critic の原型を導入し、しかもその枠組みを動物の条件づけ・神経科学との関係で論じています。
- そのMuJoCo自体、運動の制御を研究する神経科学者 Emo Todorov が作ったもの。DeepMindが2021年に買収し、2022年にApache 2.0でオープンソース化したからこそ、今日この実験を誰でも無料で走らせられる。
ベンチマークもシミュレータも、出発点は「動きと脳をどう理解するか」でした。
次回——振子が「歩く」とき、そして床が嘘をつくとき
この実験には続きがあります。(B) モデルが書けない「歩行」へ進めば、今度はRLが本当に効く領域が見えてくる。(C) さらに、シミュレータの物理が現実の床と少しズレるだけで、シミュ内で完璧だった方策が実機で転ぶ——これが sim2real ギャップです。本シリーズ「凸包」で見た 「凸包より下 ≠ 現実」 と、まったく同じ構造の谷が、ロボットの足元にもある。いま二足・四足ロコモーションの最前線が、まさにこの谷と格闘しています。次回はそこへ降りていきます。
この記事はAIが下書きし、人間が編集・公開しています。